The Power of Data in Regression Analysis
Data is the lifeblood of regression analysis, a statistical technique used to understand the relationship between variables. By examining data sets and identifying patterns, regression analysis allows us to make predictions and draw meaningful conclusions. Let’s delve into the world of data for regression analysis and explore its significance.
Types of Data
In regression analysis, we work with two main types of data: independent variables and dependent variables. Independent variables are the factors that we believe influence or predict the outcome, while dependent variables are the outcomes we are trying to predict. By collecting and analysing these data sets, we can uncover correlations and trends that help us make informed decisions.
Data Collection
The quality of data is crucial for accurate regression analysis. It is essential to collect relevant, reliable, and representative data to ensure the validity of our findings. This may involve gathering information from various sources, conducting surveys, or using existing databases. Clean and well-organised data sets are key to obtaining meaningful results.
Data Preprocessing
Before conducting regression analysis, it is important to preprocess the data to ensure its accuracy and consistency. This may involve handling missing values, removing outliers, scaling variables, and transforming data if necessary. By preparing the data effectively, we can improve the reliability of our analysis and enhance the accuracy of our predictions.
Regression Models
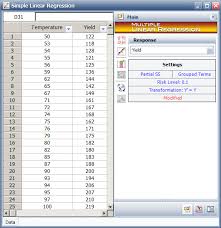
There are several types of regression models used in data analysis, including linear regression, logistic regression, polynomial regression, and more. Each model has its own assumptions and characteristics that determine its suitability for different types of data sets. By selecting the appropriate model based on our research objectives and data characteristics, we can obtain valuable insights from our analysis.
Interpreting Results
Once we have conducted regression analysis on our data sets, it is essential to interpret the results accurately. This involves examining coefficients, p-values, confidence intervals, and other statistical measures to understand the relationships between variables. By interpreting these results effectively, we can draw meaningful conclusions and make informed decisions based on our findings.
Conclusion
Data plays a fundamental role in regression analysis by enabling us to uncover patterns, relationships, and trends in our research. By collecting high-quality data sets, preprocessing them effectively, selecting appropriate models, and interpreting results accurately, we can harness the power of data to make informed decisions and drive meaningful outcomes through regression analysis.
Essential FAQs on Data for Regression Analysis
- Where to find good data for regression analysis?
- What data is needed for regression analysis?
- What is an example of a regression data?
- How do you prepare data for regression analysis?
- What is the data analysis for regression?
- What type of data is required for regression analysis?
- Which type of dataset is used in regression analysis problems?
- Which type of data is used for regression?
Where to find good data for regression analysis?
Finding good data for regression analysis is a common challenge faced by researchers and analysts. One of the primary sources for quality data is reputable databases, such as government repositories, academic institutions, and industry-specific sources. These databases often provide access to well-structured and reliable data sets that can be used for regression analysis. Additionally, conducting surveys, experiments, or collecting data from reliable sources within your field of study can also yield valuable information for analysis. It is essential to ensure that the data collected is relevant, accurate, and representative of the variables under investigation to obtain meaningful results in regression analysis.
What data is needed for regression analysis?
In the realm of regression analysis, a common query revolves around the essential data required for conducting meaningful analysis. To perform regression analysis effectively, two main types of data are crucial: independent variables and dependent variables. Independent variables represent the factors that are believed to influence or predict the outcome being studied, while dependent variables are the outcomes that researchers aim to predict or explain. Collecting accurate, relevant, and representative data sets is paramount to ensure the validity and reliability of regression analysis results. The quality of data, including its completeness and consistency, significantly influences the accuracy of predictions and insights drawn from regression models.
What is an example of a regression data?
An example of regression data could be a study examining the relationship between the amount of rainfall and crop yield in a specific region. In this scenario, the amount of rainfall would be the independent variable, while the crop yield would be the dependent variable. By collecting data on these variables over a period of time, researchers can use regression analysis to determine if there is a correlation between rainfall patterns and crop productivity. This type of regression data allows for predictive modelling and can provide valuable insights for agricultural planning and decision-making.
How do you prepare data for regression analysis?
Preparing data for regression analysis is a critical step in ensuring the accuracy and reliability of the results. To prepare data for regression analysis, it is essential to first clean the data by handling missing values, removing outliers, and checking for inconsistencies. Next, scaling variables to a similar range can help prevent bias in the analysis. Transforming variables if needed, such as using logarithmic or polynomial transformations, can improve the linearity of relationships between variables. Properly preparing the data sets by addressing these key steps ensures that the regression analysis produces meaningful and accurate insights into the relationships between variables.
What is the data analysis for regression?
Data analysis for regression involves examining and interpreting data sets to understand the relationship between variables in a regression model. It encompasses the process of collecting, preprocessing, and analysing data to identify patterns, correlations, and trends that can help predict outcomes or make informed decisions. By conducting thorough data analysis for regression, researchers can determine the strength and significance of relationships between independent and dependent variables, select appropriate regression models, interpret results accurately, and draw meaningful conclusions that contribute to a deeper understanding of the underlying data patterns.
What type of data is required for regression analysis?
In the realm of regression analysis, the type of data required is crucial for obtaining accurate and meaningful results. To conduct regression analysis effectively, two main types of data are essential: independent variables and dependent variables. Independent variables represent the factors that are believed to influence or predict the outcome, while dependent variables are the outcomes that we aim to predict. By collecting and analysing these specific data sets, we can uncover relationships, patterns, and trends that help us gain valuable insights and make informed decisions based on statistical evidence. The quality and relevance of the data used in regression analysis play a significant role in determining the reliability and validity of the results obtained from the analysis process.
Which type of dataset is used in regression analysis problems?
In regression analysis problems, the type of dataset used typically consists of two main types of variables: independent variables and dependent variables. Independent variables are the factors that are manipulated or controlled in the study, while dependent variables are the outcomes or responses that are observed and measured. The relationship between these variables is analysed to understand how changes in the independent variables affect the dependent variable. By working with this structured dataset containing both types of variables, researchers can conduct regression analysis to uncover patterns, correlations, and trends that provide valuable insights for making predictions and informed decisions.
Which type of data is used for regression?
In regression analysis, two main types of data are used: independent variables and dependent variables. Independent variables are the factors that are believed to influence or predict the outcome being studied, while dependent variables are the outcomes that are being predicted. The relationship between these two types of data is at the core of regression analysis, as it allows researchers to understand how changes in independent variables affect the dependent variable. By analysing and interpreting these data sets effectively, valuable insights can be gained to make informed decisions and predictions based on the relationships identified through regression analysis.